Rubyで始める簡単スクレイピング

Rubyを使った簡単なWebサイトスクレイピングのやり方から、対象のサイトURLや要素のxpathをtxtやcsvファイルで制御可能なサンプルプログラムの解説をしていきます。
スマホで見る
目次
まずはRubyが実行できる状態かどうかを調べる
各OS(macOS・Windows)のRubyを実行する為のプログラム解説
| OS | プログラム名称、プログラムの場所、起動の仕方など |
|---|---|
| macOS |
|
| Windows |
|
Rubyのバージョン確認をするコマンド
[macOS]ターミナル / [Windows]コマンドプロンプト
$ ruby -v
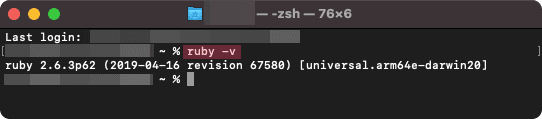
前述にある各OS毎の実行プログラム(ターミナル or コマンドプロンプト)からコマンドを実行してRubyが入っているか確認します。
macOSでのRubyバージョン確認例
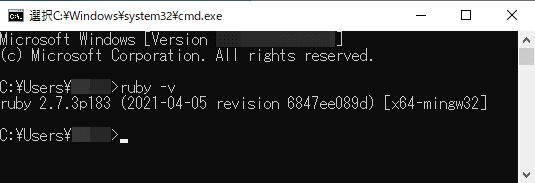
WindowsでのRubyバージョン確認例
macOSユーザーであれば最初からPCにRubyが入っているはずなので何も苦労はないはず。
WindowsユーザーはRubyをインストールした覚えがなければ以下を参考に環境を整えましょう。
WindowsのRubyインストール手順参考
簡易的なスクレイピングを体験
侍エンジニアブログさんの記事を参考に簡易的なスクレイピングを実行してみる。
スクレイピング対象は「当ブログのトップページ、2番目の記事のタイトル」を設定。
ココでやる事
- スクレイピングをするのに必要なパッケージ「Nokogiri」をインストールしてからプログラムファイル「index.rb」を作成。
- [macOS]ターミナル / [Windows]コマンドプロンプト の「cd」コマンドで「index.rb」ファイルが置かれてる場所へ移動し、「ruby index.rb」でファイルを実行。
【準備】 Nokogiriのインストール、インストールを確認
[macOS]ターミナル / [Windows]コマンドプロンプト
# Nokogiriのインストール
$ gem install nokogiri
# Nokogiriのインストールを確認
$ gem list nokogiri
【準備】 スクレイピング対象のxpathノードをコピー
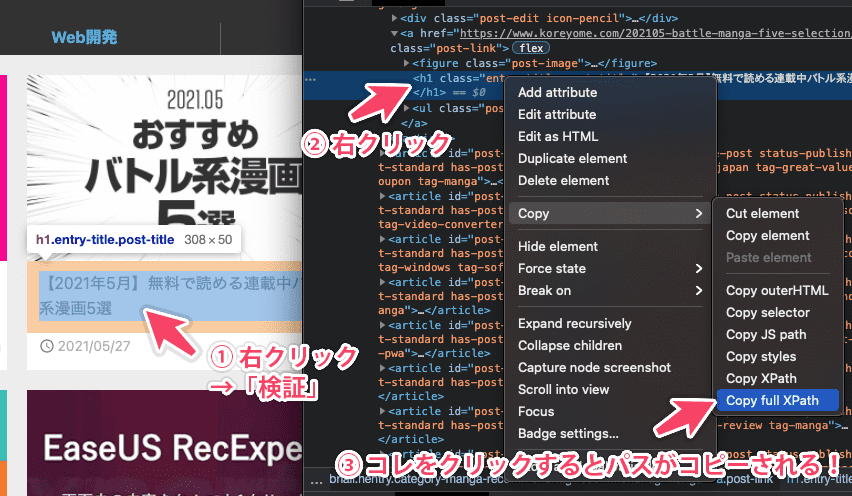
- xpathノード:
/html/body/div/div/main/section[1]/article[2]/a/h1
色々なやり方があるとは思いますが、今回はChromeブラウザを使って上図のようなやり方でパスをコピーしました。
(対象の要素上で右クリック → 検証 → 対象のタグ上で右クリック → Copy > Copy full XPath)
「index.rb」を作成後に実行
index.rb
require 'nokogiri'
require 'open-uri'
# 対象のURL
url = "https://www.koreyome.com/"
# Nokogiriで切り分け
doc = Nokogiri::HTML(open(url))
puts "### xpathノードを検索する"
doc.xpath('/html/body/div/div/main/section[1]/article[2]/a/h1').each do |link|
puts link.content
end
[macOS]ターミナル / [Windows]コマンドプロンプト
# 「index.rb」ファイルのあるディレクトリへ移動 ※「~/desktop」はmacOS用
$ cd ~/desktop
# index.rbの実行
$ ruby index.rb
実行結果
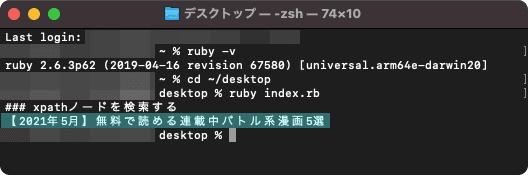
上図のように2番目の記事のタイトルテキストが表示されれば成功。
次はページ上の同様の記事要素のタイトル全てを取得するためにパスの一部を変更して実行してみます。
「index.rb」のパスの一部(article[2] → article)を変更して実行
index.rb
doc.xpath('/html/body/div/div/main/section[1]/article/a/h1').each do |link|
実行結果 ※macOSで実行した例
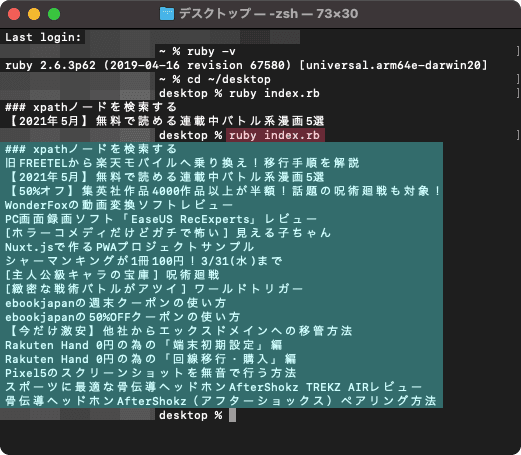
返された結果が増えていれば成功。
先程の「2番目」という指定があった部分の指定を外して、今回は対象を「記事のタイトル」と指定した為 該当するタイトルテキストが全て書き出されました。
事項ではこのプログラムを発展させたサンプルを掲載しています。
スクレイピング対象URLやxpathノードを外部ファイル上で設定を可能にしたサンプルプログラム
サンプルプログラム
| [GitHub] Ruby_scraping | 対象のサイトURLや要素のxpathをtxtやcsvファイルで制御可能なスクレイピングサンプルプログラム |
|---|---|
| [Download ZIP] | 直でファイルをダウンロード |
プログラム仕様
- プログラムの変更や実行は「index.rb」にて行う ※プログラム実行「$ ruby index.rb」
- ダウンロード直後でもサンプルサイトの記述がされているので実行後の結果をすぐに確認できる
- サンプル記述にはエラー確認の為の記述が書かれている ※実行は途中で止まらず、ドコでエラーが起きたかの結果を返すようになっている
- 「_file01_url.txt」にはスクレイピング対象サイトURLを記述 ※複数URL指定可能
- 「_file02_node.csv」にはスクレイピング対象のxpathノードを記述 ※親1・子複数設定可能
- スクレイピングが成功すると「_file03_result.csv」に結果が出力される
GitHubからプログラムのダウンロードが可能です。
ダウンロード/クローン後でもすぐに試せるようにサンプルでURLやxpathノードを記述してあります。(エラーを起こす為の記述も有り)
VSCodeからの実行結果の図
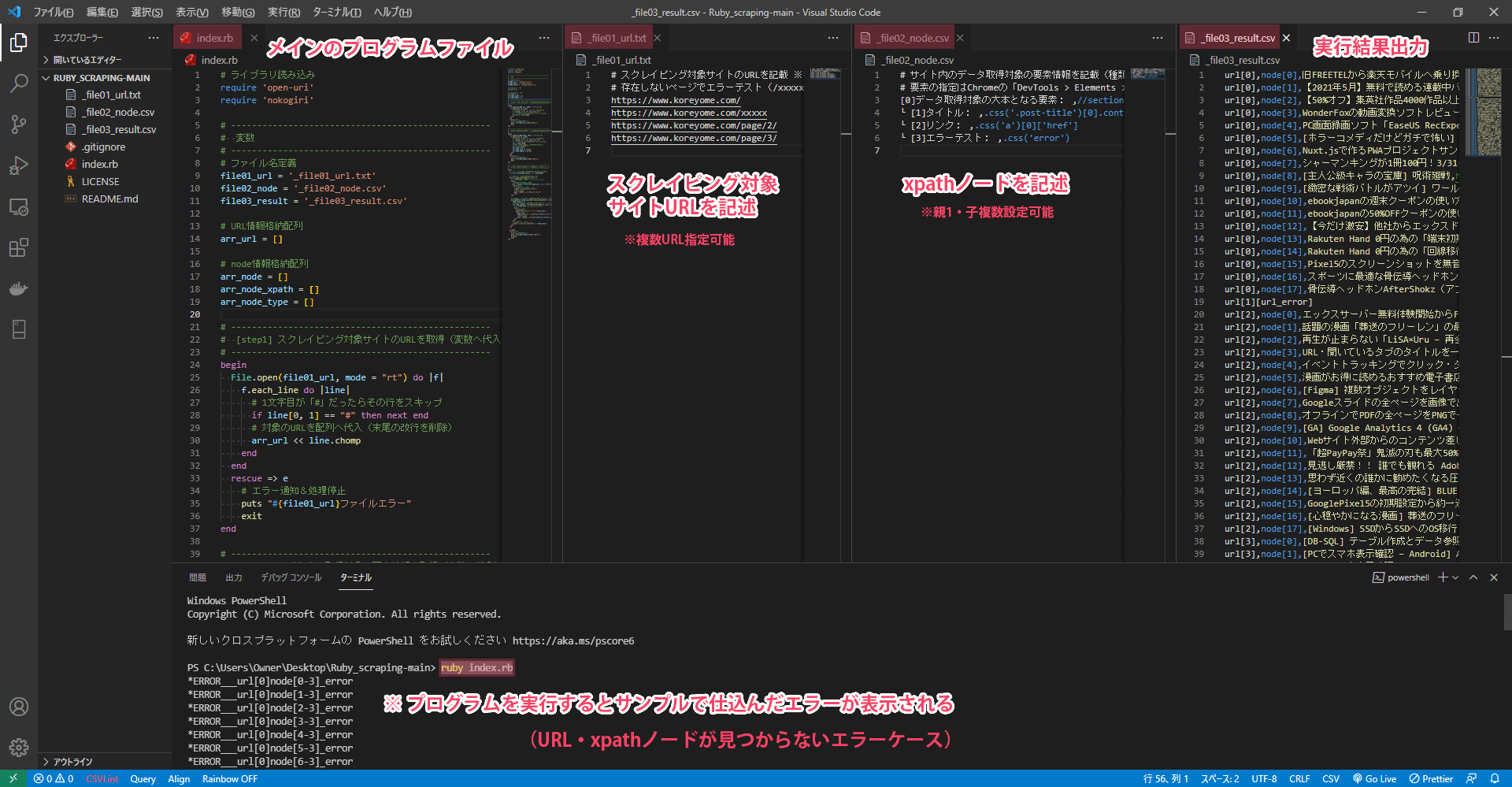
ターミナルやコマンドプロンプトからプログラムを実行しても結果は同じですが、テキストエディタの VSCode(Visual Studio Code)を使うとファイル編集とプログラム実行が一つの画面で行えるのでオススメです。
プログラムを実行するためのコマンド
$ ruby index.rb
※プログラムフォルダをVSCodeの画面上にドラッグした後必要なファイルを開きビューを分割、新しいターミナルを開いてコマンドを実行すれば図のような状態になるはずです
以上。